Early issue identification using anomaly detection on a CD pipeline - Part 1
The problem
At DataScouting (my current job), our main product Monitoring Delivery Platform is under
constant development, with new features being added and refactor work done. Our code-base is sizable and has
a lot of nuances and domain specific knowledge encoded in it. Multiple people are working on this system and
the number of microservices is ever-growing. Job scheduling and message queues make significant parts of the
system asynchronous and hard to debug.
While developing many parts of these services myself, I repeatedly felt the need for a way to test entire pipelines start to finish. Sometimes, this would be especially useful during the implementation of a feature or debugging, before anything is merged to the main branch. With an always growing team, it is getting harder to isolate the effects of changes, track down accidental side effects across services and monitor performance degradation. These issues seem to be a common in systems designed following the microservices architecture.
To give an example, our processing pipeline consists of several individual, asynchronous jobs each performed by a separate microservice, with more jobs to be added. Some may run in parallel. Some are thankfully stateless which makes the situation a bit better. The rest of our pipelines (like ingestion, reporting etc.) have similar characteristics.
Testing techniques
Looking at different testing techniques, integration tests are a good candidate and often the proposed solution. Integration tests return a great value over the invested time, as they cover big code areas. Nevertheless, it's not possible to test a change that touches the entire pipeline, across services using integration tests. Furthermore, integration tests commonly run on developer's laptops and Jenkins servers, where it is not possible to test using huge amounts of data simulating a fraction of production scale.
Another possible solution is a staging environment. A staging is surely, very useful for a number of
reasons, but it is not a controlled, repeatable environment. Also, it is tied to the develop
branch which means you can only test changes after they get merged. Finally, when trying to argue for a
hot-fix and time is of the essence, deploying to a staging and waiting for at least some data (hopefully a
good variety of cases?) to pass through the pipeline is a problem.
Ephemeral stress/load tests are an exact match for the use-case in regard to monitoring performance degradation. What we would additionally like to have is an automated system that checks the final state of various components and compares it to the values of previous runs. For example check specific database tables, documents in the index, expected paths in the file system etc.
Pipeline testing infrastructure
To try and solve the issues mentioned, earlier this year, I requested a VM. There, I set up an infrastructure that makes it possible to spin up the microservices needed by a designated pipeline and run load tests on the entire sub-system.
The user can test using any git branch they want, just by setting a few environment variables and running a
handy dandy load-test.sh script. The test cleans up artifacts of old runs, spins up the
services required and creates an artificial load surge on the fresh installation. The data for the load are
simulating real production data and, volume-wise, they can go up to the equivalent of multiple days of
production ingestion.
A single test can be run at a time, but that's an acceptable compromise. Testing the combination of ingestion and processing systems, with a load of 50k ingest actions takes less than 15 minutes.
Continuous testing and monitoring
We used this system for months manually. We would run a test and check the final state of the system ourselves for any issues or inconsistencies. Recently, I added a script that monitors our build system for successful builds of a designated (configurable) branch and executes the test automatically. This way the team can use the setup in turns, based on each one's backlog and task priority.
I also added monitoring during test execution in two different ways. A Metricbeat container monitors each individual Dockerized service as well as Postgres and RabbitMQ. Another custom script logs, on intervals, the state of crucial database tables like our task scheduling tables.
Anomaly detection
What has been missing from the setup, as said earlier, is a way to automate the detection of issues. Last week I started working on this part. I'll give an overview of the dataset structure, the first naive approach and my future plans for the system.
Dataset
Using the documents indexed by custom monitoring scripts, I can break up the timeline in separate executions, practically detecting individual load tests.
execution_spans = [{
"id": <execution_key>,
"start": <first_observation_timestamp>,
"end": <last_observation_timestamp>
}]
Then, for each execution I fetch part of the data indexed by Metrcibeat and create an entry in the dataset.
Each
entry corresponds to a different load test and contains five time series.
Tasks
A time series of the number of tasks in the system, per task type, per status.
Table counts
A time series of the number of rows, per table.
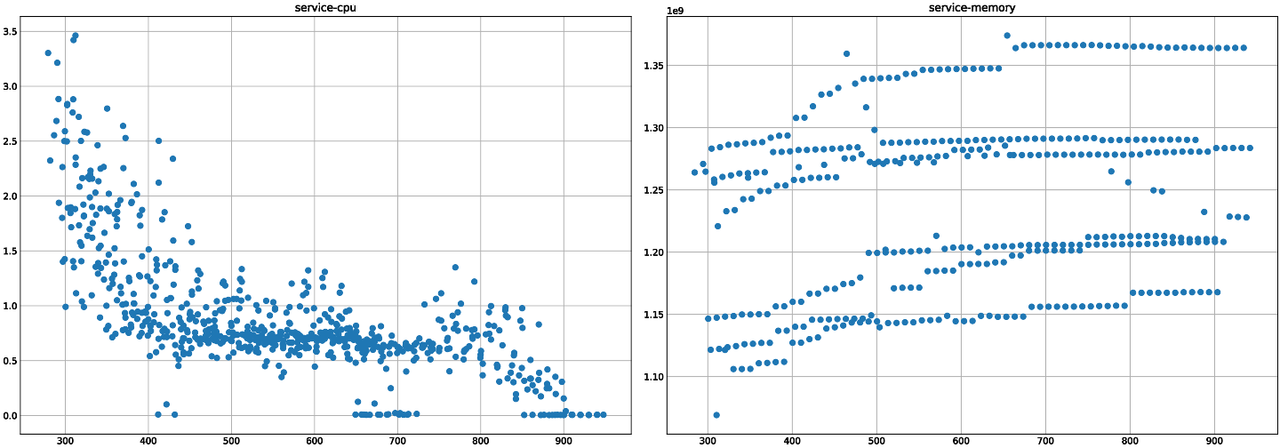
CPU usage
A time series of the CPU usage as a percentage, per service.
RAM usage
A time series of the memory usage in bytes, per service.
Disk IO [TO BE ADDED]
A time series of the disk IO in bytes, per service.
All the series have a sampling period of 10 seconds. The time is encoded as epoch seconds since execution
start.
A mock of the dataset:
{
"tasks": [[[100, 50], [100, 78]], [[110, 47], [110, 81]]],
"task_names": ["PERCOLATION-pending", "PERCOLATION-success"],
"table_counts": [[[100, 1000], [100, 73]], [[110, 1280], [110, 73]]],
"table_names": ["query_matches", "queries"],
"service_cpu": [[[100, .6], [100, .12]], [[110, .63], [110, .17]]],
"service_memory": [[[100, .41], [100, .3]], [[110, .41], [110, .34]]],
"service_disk_io": [[[100, 0], [100, 1256]], [[110, 0], [110, 2134]]],
"services": ["persistence-manager", "percolation"]
}
Detection
For anomaly detection, I used the Isolation Forest model implemented by scikit-learn. I train multiple models, one for each service and for each metric. This way I can get granularity along the lines of:
-
the percolation service produced the expected results, detected by the model running on
table_counts - used the expected amount of RAM, detected by the model running on this service's memory time series, but
- had abnormal CPU usage, detected by the model running on this service's CPU usage time series
Isolation forest is very fast to train and use, so doing this for 30+ models is not close to being an issue.
Results
This initial work is just an attempt to bootstrap the system and get going with anomaly detection. The results are, expectedly, not great. The current dataset is not big enough (~15 test runs), while there are a lot of bad runs included, resulting in a big percentage of outliers on the existing data. The predictions are volatile to small changes in the series.
A lot of work can be done on:
- better configuring the pipeline services, currently the defaults are used
- figuring out the best volume for the load used on each test
- selecting the dataset features used
- selecting the level of aggregation of the time series
- using more sophisticated models and techniques
- parameterizing the models
On the positive side, the complete process from feature extraction to prediction and output requires only a few seconds (though this might change depending on the models used in the future). The data collected so far present some variability, but seem to mostly follow distinct, characteristic curves. Based on that, we might not achieve great results on the detection of small memory leaks, lost CPU cycles etc. But we will definitely be able to detect major problems.
Finally, I also laid out the initial work for a report generation system that outputs an HTML. The page is then served by an nginx container, so the person that is using the system has easy access to the results.